CUDA é uma plataforma de desenvolvimento da NVIDIA com o proposito de facilitar o desenvolvimento de aplicações para processamento paralelo utilizando GPU's de proposito geral.


Nome: Gabriel Oliveira
E-mail: gahskp@gmail.com
Nome: Luan Michel
E-mail: luanmichel96@gmail.com
Arquitetura

DISTRIBUIÇÃO DE TRANSISTORES EM CPU E GPU.
Pode-se perceber que uma GPU contempla maior parte de seus transistores para diversos núcleos independentes de ALU (Arithmetic Logic Unit – Unidade Lógica Aritmética), cache e controle. Desse modo uma GPU é bastante eficiente em aplicativos que trabalham com cálculos matemáticos com alto grau de independência entre eles de modo que os cálculos possam ser distribuídos em diversos núcleos paralelamente.
API E PROGRAMAS CUDA
Executar programas em CUDA requer alguns componentes de hardware e software. Para hardware, pode-se contar com diversos dispositivos GPU habilitadas pela NVIDIA a executar programas CUDA. Em software é necessário de um driver e um toolkit com um compilador e outras ferramentas, ambos disponibilizados pela NVIDIA para download em seu website.
A figura a seguir, ilustra como é a disposição em camadas dos componentes necessários para execução em CUDA.

A pilha de software da plataforma.
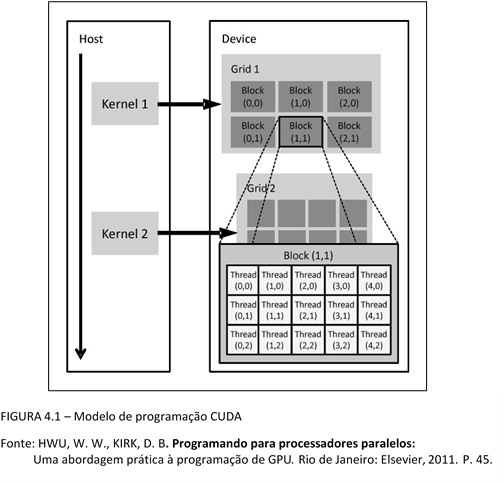
Um programa cuda é dividido em diversas partes, sendo elas seriais e paralelas. As fases seriais, chamadas hosts, são executadas pela CPU, e as seções paralelas, denominadas device, são executadas pela GPU. O modelo SPMD utilizado por CUDA permite executar funções com dados paralelos, os kernels. A estrutura da arquitetura se dá da seguinte forma:
- Kernel: O programador possui a possibilidade de criar funções chamadas de kernel. Estas funções podem ser executadas N vezes em paralelo por N diferentes CUDA Threads.
- Thread Hierarchy (Hierarquia de Threads): threadIdx é necessário para criar um bloco de threads. É na verdade um vetor de três componentes, podendo ter uma dimensão (vetor), duas dimensões (matriz) e três dimensões (volume) para criar o bloco.
- Grade: Uma estrutura que organiza todos os elementos de um mesmo kernel, com elementos menores, chamados de blocos;
- Memory Hierarchy (Hierarquia de Memória): Cada thread acessa dados de múltiplas posições de memória em sua execução. E cada uma delas possui sua memória local privada, da mesma forma que um bloco de threads tem uma memória compartilhada a qual é visível todas as threads do bloco. E por fim, todas as threads tem acesso a uma memória global. Sendo a primeira a memória menos lenta e a última a mais lenta.