A grande história do Apache Spark

O Spark é um framework para processamento de Big Data construído com foco em velocidade, facilidade de uso e análises sofisticadas. Está sendo desenvolvido desde de 2009 pelo AMPLab da Universidade de Califórnia em Berkeley e em 2010 seu código foi aberto como projeto da fundação Apache.
Inicialmente, o Spark oferece um framework unificado e de fácil compreensão para gerenciar e processar Big Data com uma variedade de conjuntos de dados de diversas naturezas (por exemplo: texto, grafos, etc), bem como de diferentes origens (batch ou streaming de dados em tempo real).

O Spark permite que aplicações em clusters Hadoop executem até 100 vezes mais rápido em memória e até 10 vezes mais rápido em disco.
Inicialmente, o Spark oferece um framework unificado e de fácil compreensão para gerenciar e processar Big Data. Com uma variedade de conjuntos de dados de diversas naturezas bem como de diferentes origens
O Hadoop já existe a mais de 10 anos e tem provado ser a melhor solução para o processamento de grandes conjuntos de dados.
O MapReduce, é uma ótima solução para cálculos de único processamento, mas não muito eficiente para os casos de uso que requerem cálculos e algoritmos com várias execuções.
Hadoop incluem tipicamente clusters que são difíceis de configurar e gerenciar, além de precisar da integração de várias ferramentas para diferentes casos de uso de Big Data.
O Spark permite que os programadores desenvolvam pipelines compostos por várias etapas complexas usando grafos direcionais acíclicos.
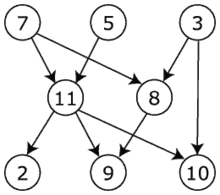
Além disso, suporta o compartilhamento de dados da memória através desses grafos, de modo que os diferentes jobs possam trabalhar com os mesmos dados.
Devemos olhar para o Spark como uma alternativa para MapReduce do Hadoop em vez de um simples substituto, mas como uma solução abrangente e unificada para gerenciar diferentes casos de uso da Big Data.