Apache Spark ™ é um mecanismo de análise unificado para processamento de dados em grande escala.
Apache Spark é um framework de código fonte aberto para computação distribuída. Foi desenvolvido no AMPLab da Universidade da Califórnia e posteriormente repassado para a Apache Software Foundation que o mantém desde então. Spark provê uma interface para programação de clusters com paralelismo e tolerância a falhas.
O Apache Spark oferece suporte nativo a Java, Scala, SQL e Python, oferecendo a você várias linguagens para a criação de aplicativos. Além disso, você pode enviar consultas SQL ou HiveQL usando o módulo Spark SQL. Além de executar aplicativos, você pode usar a API do Spark de modo interativo com Python ou Scala diretamente no shell do Spark ou por meio de blocos de anotações Jupyter no seu cluster.
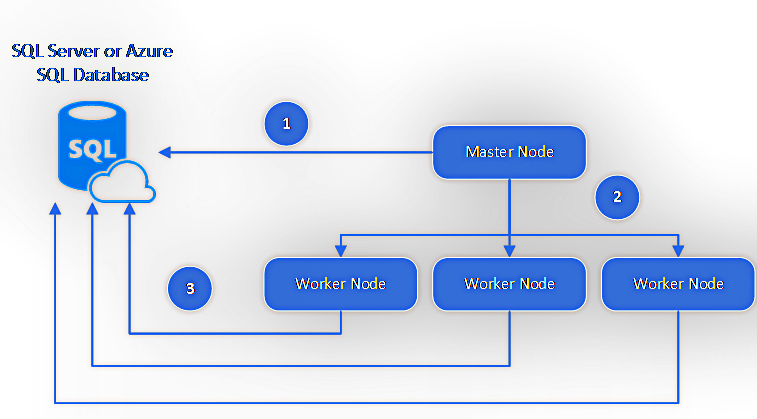
O suporte ao Apache Hadoop 3.0 no EMR 6.0 proporciona o suporte a contêineres do Docker para simplificar o gerenciamento de dependências. Você também pode utilizar blocos de anotações do EMR independentes de clusters (baseado no Jupyter) ou usar o Zeppelin para criar blocos de anotações interativos e colaborativos para a exploração e a visualização de dados. É possível ajustar e depurar cargas de trabalho no console do EMR, que conta com um Spark History Server fora do cluster e persistente.
Casos de uso

O Apache Spark inclui o MLlib para vários algoritmos de machine learning escaláveis ou você pode usar suas próprias bibliotecas. Ao armazenar conjuntos de dados na memória durante um trabalho, o Spark obtém excelente performance para consultas iterativas comuns em cargas de trabalho de machine learning

Use o Spark SQL para consultas interativas de baixa latência com SQL ou HiveQL. O Spark no EMR pode utilizar o EMRFS para que você tenha acesso ad hoc aos seus conjuntos de dados no S3. Além disso, você pode usar blocos de anotações do EMR ou do Zeppelin, ou ferramentas de BI por meio de conexões ODBC e JDBC.
Características do Apache Spark
 Estende o MapReduce evitando mover os dados durante o processamento.
Estende o MapReduce evitando mover os dados durante o processamento.- O desempenho pode ser várias vezes mais rápido do que outras tecnologias de Big Data.
- Há suporte para validação sob demanda de consultas para Big Data.
- O Spark detém resultados intermediários na memória, em vez de escrevê-los no disco.
- Executa operações em disco quando os dados não cabem mais na memória.
- Armazenará a maior quantidade possível de dados na memória e, em seguida, irá persisti-los em disco.
- Suporta mais do que apenas as funções de MapReduce.
- Otimiza o uso de operadores de grafos arbitrários.
- Avaliação sob demanda de consultas de Big Data contribui com a otimização do fluxo global do processamento de dados.
- Fornece API’s concisas e consistentes em Scala, Java e Python.
- Oferece shell interativo para Scala e Python. O shell ainda não está disponível em Java.
O Spark é escrito na linguagem Scala e executa em uma máquina virtual Java. Atualmente, suporta as seguintes linguagens para o desenvolvimento de aplicativos:

Bibliotecas do Spark

O Spark Streaming pode ser usado para processar dados de streaming em tempo real baseado na computação de microbatch. Para isso é utilizado o DStream que é basicamente uma série de RDD para processar os dados em tempo real.
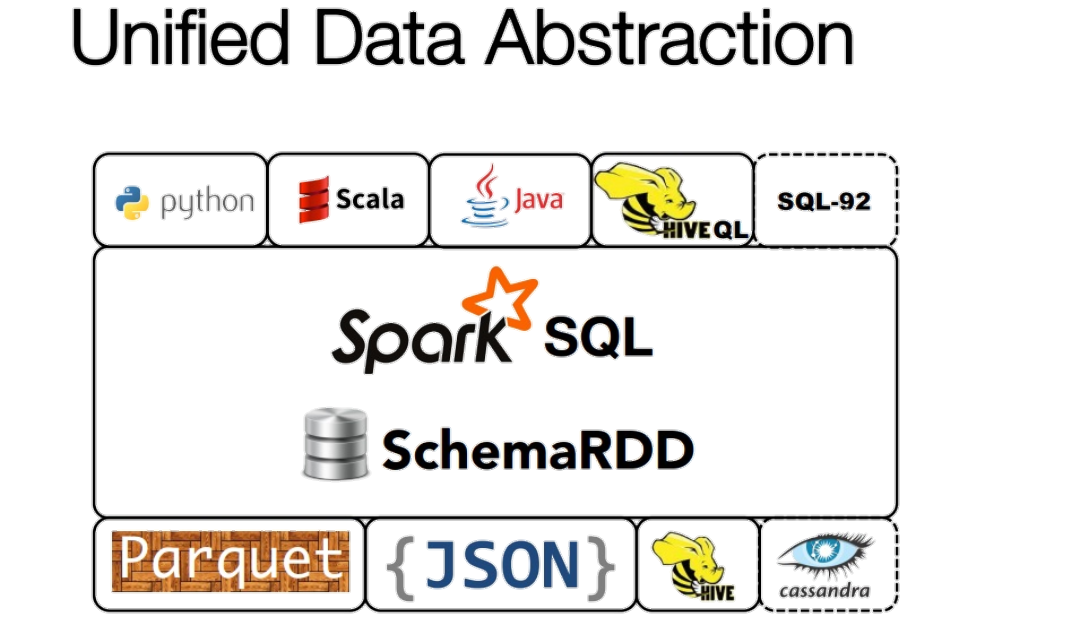
Spark SQL fornece a capacidade de expor os conjuntos de dados Spark através de uma API JDBC. Isso permite executar consultas no estilo SQL sobre esses dados usando ferramentas tradicionais de BI e de visualização. Além disso, também permite que os usuários usem ETL para extrair seus dados em diferentes formatos (como JSON, Parquet, ou um banco de dados), transformá-los e expô-los para consultas ad-hoc;
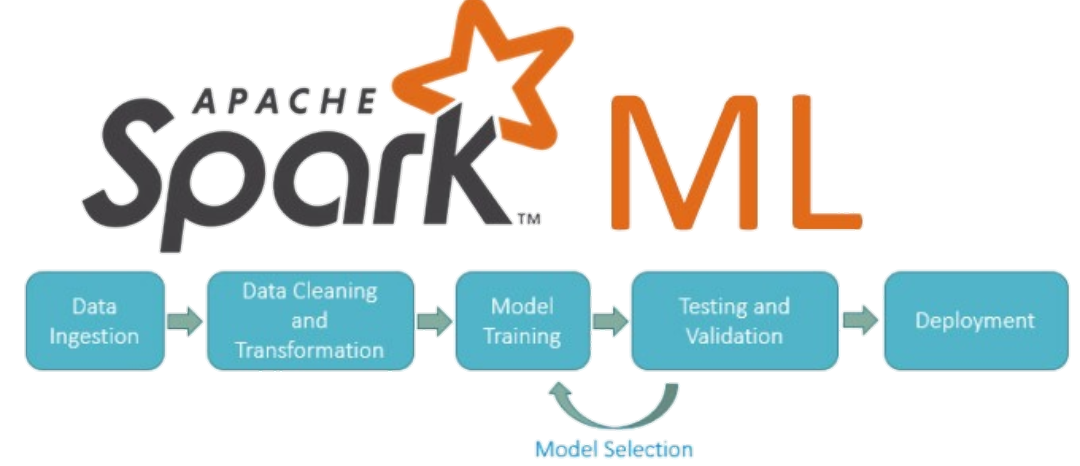
MLlib é a biblioteca de aprendizado de máquina do Spark, que consiste em algoritmos de aprendizagem, incluindo a classificação, regressão, clustering, filtragem colaborativa e redução de dimensionalidade;

GraphX é uma nova API do Spark para grafos e computação paralela. Em alto nível, o GraphX estende o Spark RDD para grafos. Para apoiar a computação de grafos, o GraphX expõe um conjunto de operadores fundamentais (por exemplo, subgrafos e vértices adjacentes), bem como uma variante optimizada do Pregel. Além disso, o GraphX inclui uma crescente coleção de algoritmos para simplificar tarefas de análise de grafos.
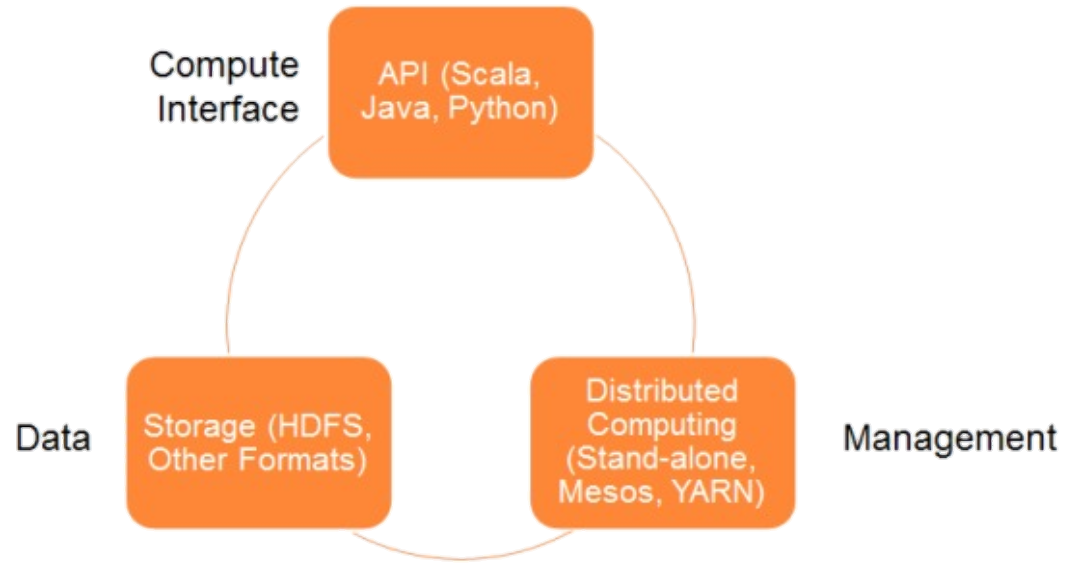
Arquitetura do Spark
Inclui os seguintes componentes:
ARMAZENAMENTO DE DADOS:
> O Spark usa sistema de arquivos HDFS para armazenamento de dados. Funciona com qualquer fonte de dados compatível com Hadoop, incluindo o próprio HDFS, HBase, Cassandra, etc.
API:
> A API permite que os desenvolvedores de aplicações criem aplicações baseadas no Spark usando uma interface de API padrão para Scala, Java e Python.
GESTÃO DE RECURSOS:
> O Spark pode ser implantado como um servidor autônomo ou em uma estrutura de computação distribuída como o Mesos ou o YARN.
Operações do conjunto de dados do Spark
TRANSFORMAÇÃO
> Não retornam um único valor, mas um novo RDD. Nada é avaliado quando a função de transformação é chamada, ela apenas recebe um RDD e retorna um novo RDD.
AÇÃO
> Esta operação avalia e retorna um novo valor. Quando uma função de ação é chamada em um objeto RDD, todas as consultas de processamento de dados são computadas e o valor é retornado.
Variáveis compartilhadas do Spark
O Spark oferece dois tipos de variáveis compartilhadas para torná-lo eficiente para execução em cluster. Estas variáveis são dos tipos Broadcast e Acumuladores.
BROADCAST
> Também chamadas de variáveis de difusão, permitem manter variáveis somente leitura no cache de cada máquina em vez de enviar uma cópia junto com as tarefas. Essas variáveis podem ser usadas para dar aos nós do cluster as cópias de grandes conjuntos de dados. O seguinte trecho de código mostra como usar as variáveis de broadcast:
// //Variáveis de Broadcast // val broadcastVar = sc.broadcast(Array(1, 2, 3)) broadcastVar.value
ACUMULADORES
> Permitem a criação de contadores ou armazenar os resultados de somas. As tarefas em execução no cluster podem adicionar valores à variável do acumulador usando o método add. No entanto, as tarefas distintas não podem ler o seu valor pois apenas o programa principal pode ler o valor de um acumulador. O trecho de código a seguir mostra como usar/criar um acumulador:
// //Acumulador // val accum = sc.accumulador(0, "My Accumulador") sc.parallelize(Array(1, 2, 3, 4)).foreach(x => accum += x) accum.value