O Apache Beam é baseado em dois métodos de processamento de dados: batch processing (Processamento em Lote) e stream processing (Processamento em Fluxo).
Batch processing é o processamento de transações em grupos ou lotes (batches). Não é necessária interação com o usuário após o processamento ter sido iniciado, o que diferencia o mesmo de processamentos de transações habituais, que necessitam de interação contínua com um usuário, além de realizar cada uma das transações individualmente.
As mecânicas de processamento em lote envolvem alimentar com diversos comandos e direções que o mesmo deve seguir, de forma a automatizar o processo o máximo possível e minimizar a interação humana, portanto sendo muito utilizado em grandes corporações atualmente.
O software identifica erros através de exceções, que funcionam realizando um monitoramento do último processamento feito. Devido a essa característica, apesar de poder ser realizado a qualquer momento, processamentos em lote são indicados para o fim do ciclo de um processamento de dados, como no fim de um dia ou na geração mensal de boletos.
O processamento de fluxo (stream) é o processamento contínuo de dados gerados por diversas fontes, ao usar este tipo de processamento os dados podem ser processados, arquivados e analisados em tempo real.
O termo streaming é utilizado para descrever fluxos de dados contínuos, sem começo ou fim, que oferecem dados que podem ser utilizados sem a necessidade de realizar download. Uma analogia comum a ser realizada é como a água corre em um rio, os fluxos veem de várias fontes, variando em velocidade e volume e se combinam em um único fluxo contínuo.
De forma semelhante os fluxos de dados são gerados de diversas fontes, em vários formatos e volumes, e podem ser agregados para sua análise em tempo real. As aplicações que analisam e processam os dados precisam processar cada pacote por vez, sendo que as mesmas devem ser capazes de guardar grandes volumes de dados em ordem sequencial de forma consistente para que a interação com os dados ocorra.
Streaming é caracterizado pela forma em que tipos de dados e processamento de dados no tempo são ilimitados. Porém, devido ao seu uso de dados de ponto flutuante, stream processing gera resultados aproximados. A falta de acuracidade desse método leva a seu uso em conjunto de batch processing, método que fornece dados mais exatos em troca da flexibilidade de streaming.
A dificuldade de utilizar ambos streaming e batch systems é a necessidade de manter duas versões do pipeline de dados e depois juntar os resultados. A solução: união dos conceitos de processamento em lote e processamento em fluxo em um novo modelo, chamado Dataflow.
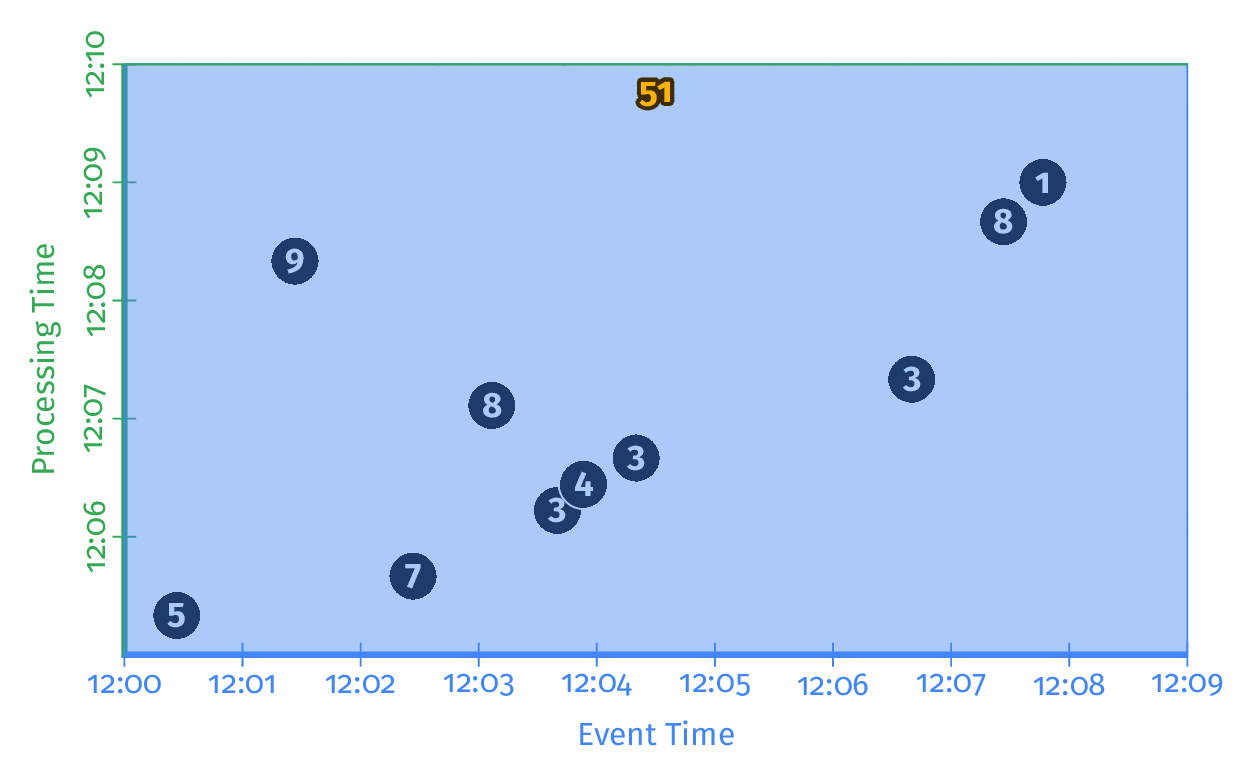
O processamento de dados pode ser representado pelo tempo de evento e o tempo de processamento. O tempo de evento descreve o momento no qual um evento ocorreu, enquanto o tempo de processamento descreve o momento no qual um evento foi efetivamente observado pelo sistema.
O modelo Dataflow pode ser representado através de gráficos de tempo de processamento por tempo de evento que respondem quatro perguntas sobre o processamento de dados: o que, onde, quando e como.
O gráfico demonstra o cálculo de resultados em uma única janela de tempo, conceito utilizado no batch processing clássico.
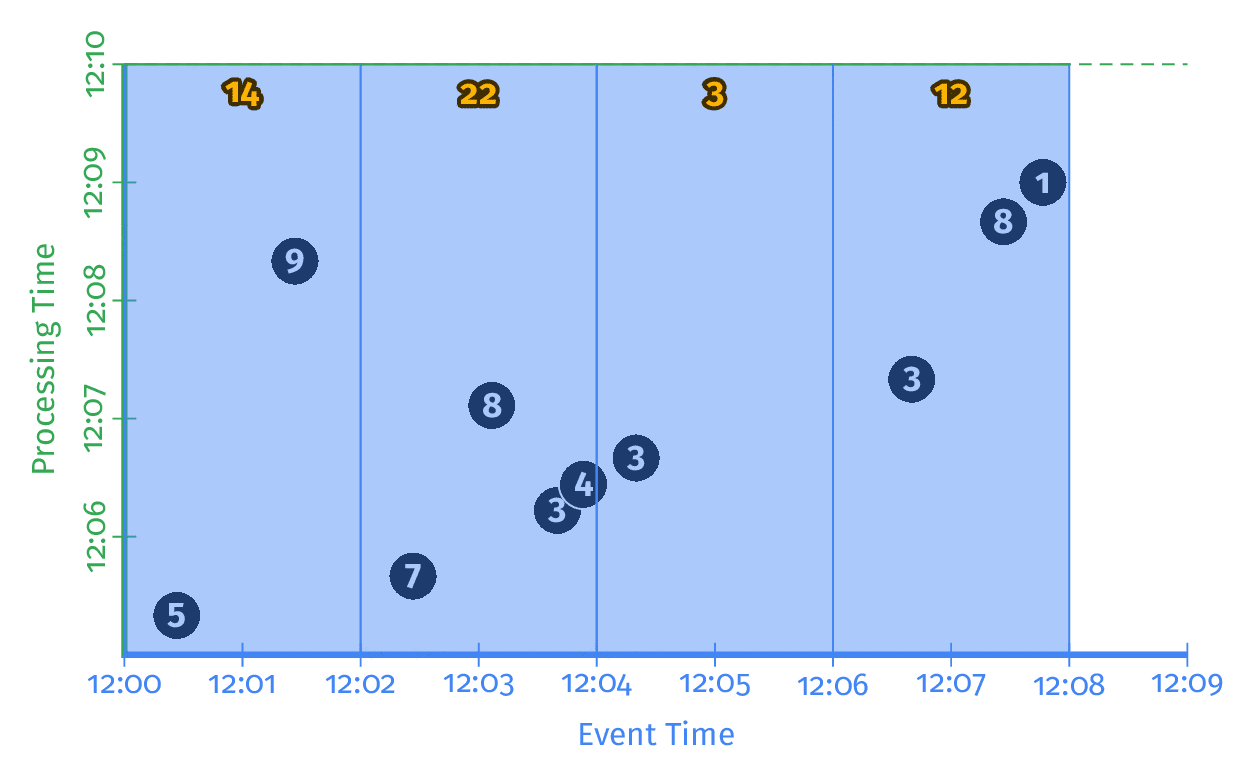
O gráfico demonstra o cálculo de resultados em múltiplas janelas de tempo, conceito utilizado no em windowed batch.
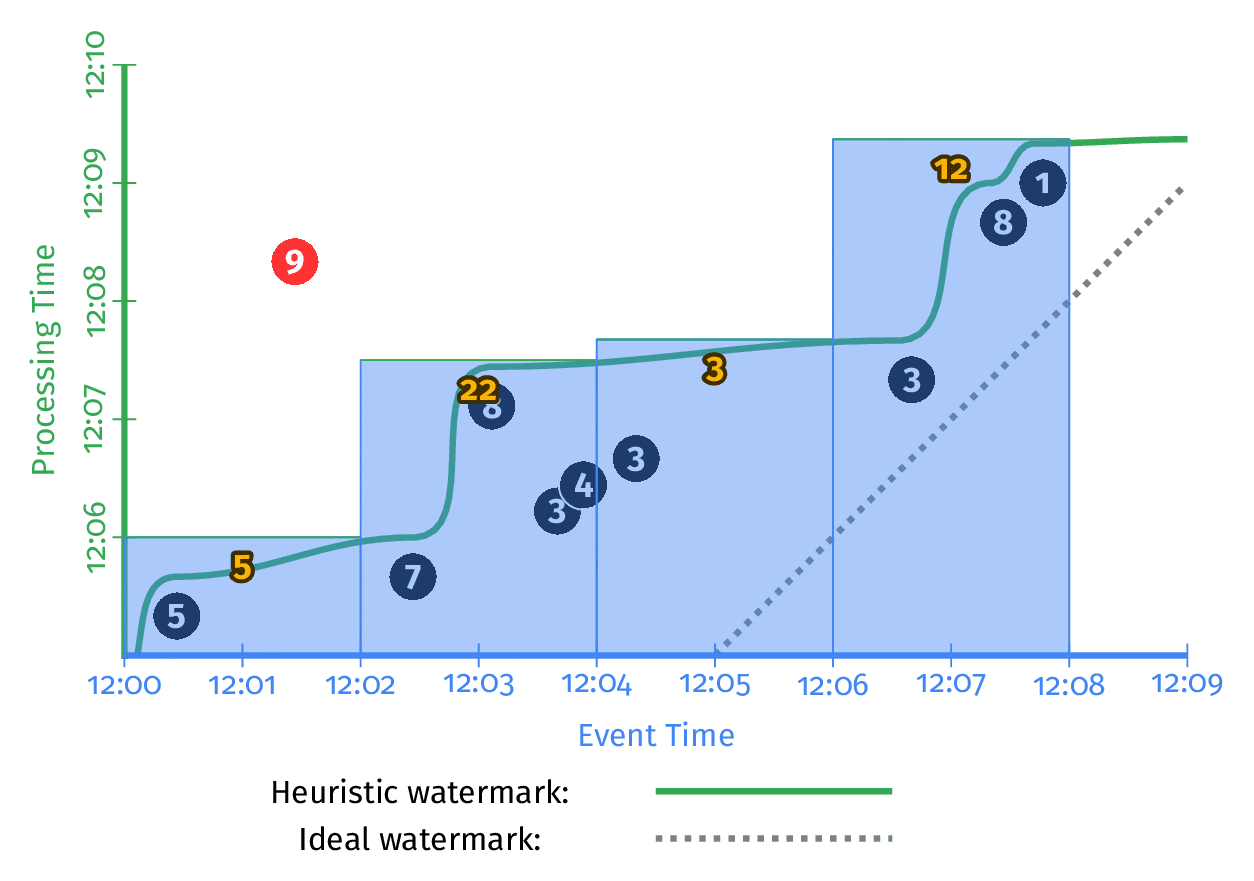
O gráfico demonstra o conceito de streaming.
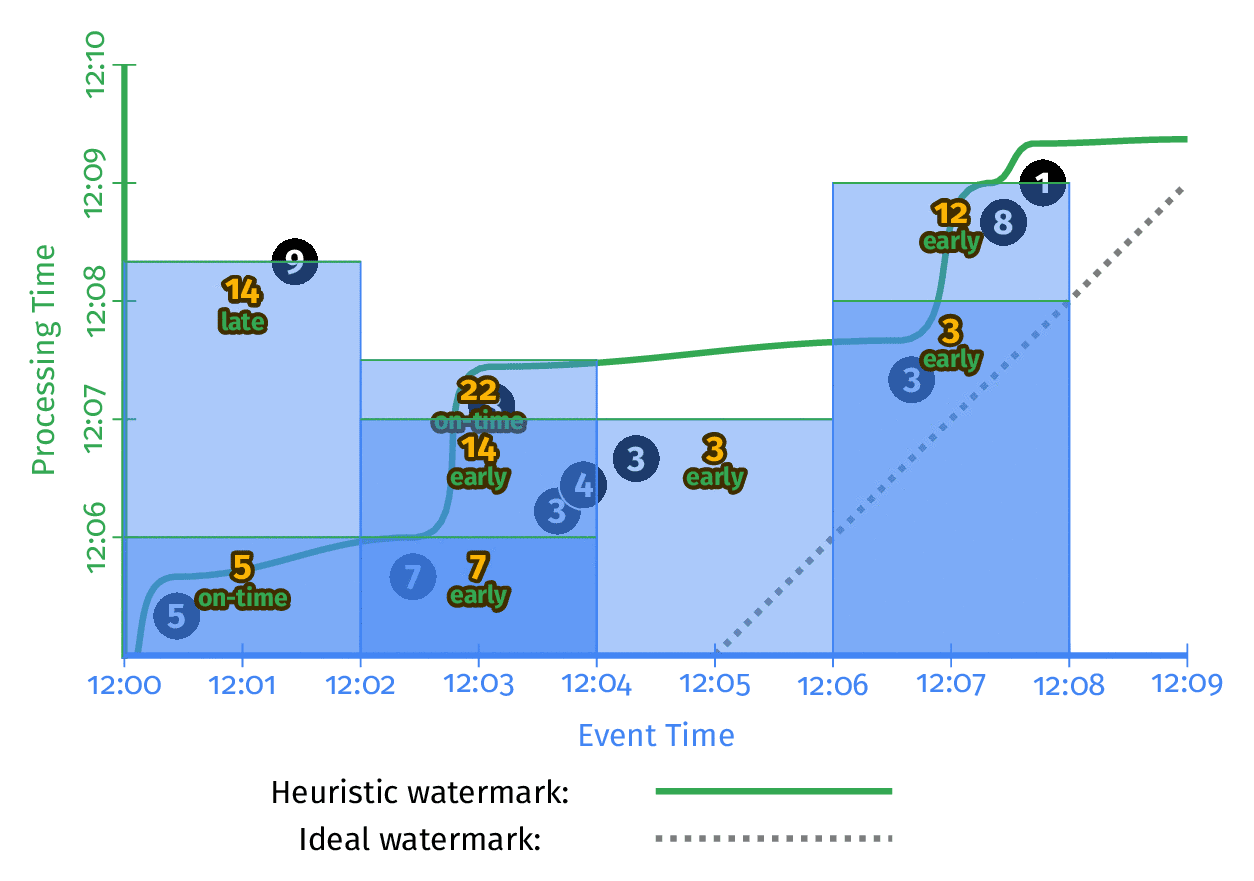
O gráfico demonstra uma forma avançada de streaming que utiliza conceitos de acumulação.
Através da separação concisa dessa quatro perguntas, o Modelo Dataflow utilizado pelo Apache Beam pode descrever diferentes cenários de processamento de dados com a simples alteração de certas linhas de código.