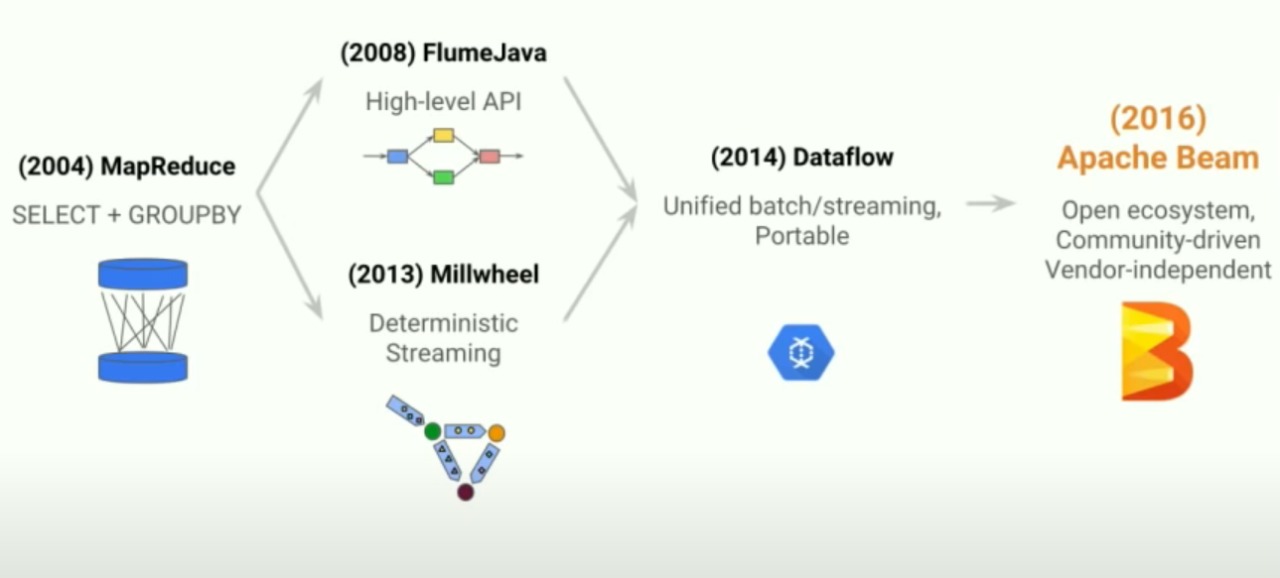
Apache Beam é o último projeto open source da Apache consiste em um modelo de programação unificada pra processamento portátil e eficiente de pipeline. O mesmo se originou em 2004, quando a Google criou o MapReduce, que era um modelo de programação de processamento de dados distribuídos, porém este era muito simples e funcionava basicamente apenas como seletor e agrupador de dados, não sendo muito útil.
O Dataflow evoluiu em duas direções, primeiramente em 2008 foi criado o FlumeJava, que utilizava-se de IPA de alto nível para que pudessem ser construídos grafos a partir dos dados e a partir dos mesmos pudessem ser processados de modo paralelo. A outra direção na qual o Dataflow evoluiu foi o Meelwheel, um sistema de processamento de fluxo criado em 2013, cujo foco era derrubar a ideia de processamento de fluxo deveria ser aproximado e torná-lo determinístico e exato, isso era possível graças a ideia de fazer os processos ocorrerem quando certos eventos acontecessem, em vez de sua ativação ser feita quando um pipeline específico os visse.
Em 2014 esses dois modelos foram unificados no Dataflow, que permitia tanto batch processing, quanto streaming processing em apenas um modelo. O mesmo também tem como ideia ser portátil, ou seja, é possível executar os pipelines em mais de um Dataflow. Em 2016 o Dataflow culminou no ApacheBeam.
Linha do tempo do desenvolvimento do Apache Beam.